





C++ || Custom Template Hash Table With Iterator Using Separate Chaining

Looking for sample code for a Hash Map? Click here!
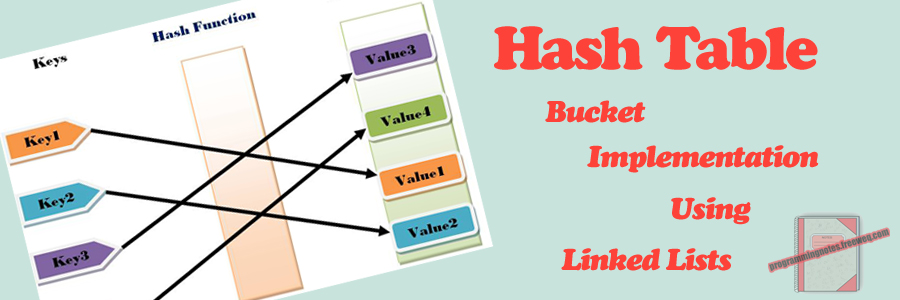
Before we get into the code, what is a Hash Table? Simply put, a Hash Table is a data structure used to implement an associative array; one that can map unique “keys” to specific values. While a standard array requires that indice subscripts be integers, a hash table can use a floating point value, a string, another array, or even a structure as the index. That index is called the “key,” and the contents within the array at that specific index location is called the value. A hash table uses a hash function to generate an index into the table, creating buckets or slots, from which the correct value can be found.
To illustrate, compare a standard array full of data (100 elements). If the position was known for the specific item that we wanted to access within the array, we could quickly access it. For example, if we wanted to access the data located at index #5 in the array, we could access it by doing:
array[5]; // do something with the data
Here, we dont have to search through each element in the array to find what we need, we just access it at index #5. The question is, how do we know that index #5 stores the data that we are looking for? If we have a large set of data, doing a sequential search over each item within the array can be very inefficient. That is where hashing comes in handy. Given a “key,” we can apply a hash function to a unique index or bucket to find the data that we wish to access.
So in essence, a hash table is a data structure that stores key/value pairs, and is typically used because they are ideal for doing a quick search of items.
Though hashing is ideal, it isnt perfect. It is possible for multiple items to be hashed into the same location. Hash “collisions” are practically unavoidable when hashing large data sets. The code demonstrated on this page handles collisions via separate chaining, utilizing an array of linked list head nodes to store multiple values within one bucket – should any collisions occur.
An iterator was also implemented, making data access that much more simple within the hash table class. Click here for an overview demonstrating how custom iterators can be built.
Looking for sample code for a Hash Map? Click here!
=== CUSTOM TEMPLATE HASH TABLE WITH ITERATOR ===
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188189190191192193194195196197198199200201202203204205206207208209210211212213214215216217218219220221222223224225226227228229230231232233234235236237238239240241242243244245246247248249250251252253254255256257258259260261262263264265266267268269270271272273274275276277278279280281282283284285286287288289290291292293294295296297298299300301302303304305306307308309310311312313314315316317318319320321322323324325326327328329330331332333334335336337338339340341342343344345346347348349350351352353354355356357358359360361362363364365366367368369370371372373374375376377378379380381382383384385386387388389390391392393394395396397398399400401402403404405406407408409410411412413414415416417418419420421422423424425426427428429430431432433434435436437438439440441442443444445446447448449450451452453454455456457458459460461462463464465466467468469470471472473474475476
// ============================================================================// Author: Kenneth Perkins// Date: Jan 18, 2013// Taken From: http://programmingnotes.org/// File: HashTable.h// Description: This is a class which implements various functions which// demonstrates the use of a Hash Table.// ============================================================================#ifndef TEMPLATE_HASH_TABLE#define TEMPLATE_HASH_TABLE#include <iostream>#include <string>#include <sstream>#include <cstdlib> // if user doesnt define, this is the// default hash table sizeconst int HASH_SIZE = 100; template <class ItemType>class HashTable{public: HashTable(int hashSze = HASH_SIZE); /* Function: Constructor initializes hash table Precondition: None Postcondition: Defines private variables */ bool IsEmpty(int key); /* Function: Determines whether hash table is empty at the given key Precondition: Hash table has been created Postcondition: The function = true if the hash table is empty and the function = false if hash table is not empty */ bool IsFull(); /* Function: Determines whether hash table is full Precondition: Hash table has been created Postcondition: The function = true if the hash table is full and the function = false if hash table is not full */ int Hash(ItemType newItem); /* Function: Computes and returns a unique hash key for a given item The returned key is the given cell where the item resides Precondition: Hash table has been created and is not full Postcondition: The hash key is returned */ void Insert(ItemType newItem); /* Function: Adds newItem to the back of the list at a given key in the hash table A unique hash key is automatically generated for each newItem Precondition: Hash table has been created and is not full Postcondition: Item is in the hash table */ void Append(int key, ItemType newItem); /* Function: Adds new item to the end of the list at a given key in the hash table Precondition: Hash table has been created and is not full Postcondition: Item is in the hash table */ bool Remove(ItemType deleteItem, int key = -1); /* Function: Removes the first instance from the table whose value is "deleteItem" Optional second parameter indicates the key where deleteItem is located Precondition: Hash table has been created and is not empty Postcondition: The function = true if deleteItem is found and the function = false if deleteItem is not found */ void Sort(int key); /* Function: Sort the items in the table at the given key Precondition: Hash table has been initialized Postcondition: The hash table is sorted */ int TableSize(); /* Function: Return the size of the hash table Precondition: Hash table has been initialized Postcondition: The size of the hash table is returned */ int TotalElems(); /* Function: Return the total number of elements contained in the hash table Precondition: Hash table has been initialized Postcondition: The size of the hash table is returned */ int BucketSize(int key); /* Function: Return the number of items contained in the hash table cell at the given key Precondition: Hash table has been initialized Postcondition: The size of the given key cell is returned */ int Count(ItemType searchItem); /* Function: Return the number of times searchItem appears in the table. Only works on items located in their correctly hashed cells Precondition: Hash table has been initialized Postcondition: The number of times searchItem appears in the table is returned */ void MakeEmpty(); /* Function: Initializes hash table to an empty state Precondition: Hash table has been created Postcondition: Hash table no longer exists */ ~HashTable(); /* Function: Removes the hash table Precondition: Hash table has been declared Postcondition: Hash table no longer exists */ // -- ITERATOR CLASS -- class Iterator; /* Function: Class declaration to the iterator Precondition: Hash table has been declared Postcondition: Hash Iterator has been declared */ Iterator begin(int key){return(!IsEmpty(key)) ? head[key]:NULL;} /* Function: Returns the beginning of the current hash cell list Precondition: Hash table has been declared Postcondition: Hash cell has been returned to the Iterator */ Iterator end(int key=0){return NULL;} /* Function: Returns the end of the current hash cell list Precondition: Hash table has been declared Postcondition: Hash cell has been returned to the Iterator */ private: struct node { ItemType currentItem; node* next; }; node** head; // array of linked list declaration - front of each hash table cell int hashSize; // the size of the hash table (how many cells it has) int totElems; // holds the total number of elements in the entire table int* bucketSize; // holds the total number of elems in each specific hash table cell}; //========================= Implementation ================================// template<class ItemType>HashTable<ItemType>::HashTable(int hashSze){ hashSize = hashSze; head = new node*[hashSize]; bucketSize = new int[hashSize]; for(int x=0; x < hashSize; ++x) { head[x] = NULL; bucketSize[x] = 0; } totElems = 0;}/* End of HashTable */ template<class ItemType>bool HashTable<ItemType>::IsEmpty(int key){ if(key >=0 && key < hashSize) { return head[key] == NULL; } return true;}/* End of IsEmpty */ template<class ItemType>bool HashTable<ItemType>::IsFull(){ try { node* location = new node; delete location; return false; } catch(std::bad_alloc&) { return true; }}/* End of IsFull */ template<class ItemType>int HashTable<ItemType>::Hash(ItemType newItem){ long h = 19937; std::stringstream convert; // convert the parameter to a string using "stringstream" which is done // so we can hash multiple datatypes using only one function convert << newItem; std::string temp = convert.str(); for(unsigned x=0; x < temp.length(); ++x) { h = (h << 6) ^ (h >> 26) ^ temp[x]; } return abs(h % hashSize);} /* End of Hash */ template<class ItemType>void HashTable<ItemType>::Insert(ItemType newItem){ if(IsFull()) { //std::cout<<"nINSERT ERROR - HASH TABLE FULLn"; } else { int key = Hash(newItem); Append(key,newItem); }}/* End of Insert */ template<class ItemType>void HashTable<ItemType>::Append(int key, ItemType newItem){ if(IsFull()) { //std::cout<<"nAPPEND ERROR - HASH TABLE FULLn"; } else { node* newNode = new node; // adds new node newNode-> currentItem = newItem; newNode-> next = NULL; if(IsEmpty(key)) { head[key] = newNode; } else { node* tempPtr = head[key]; while(tempPtr-> next != NULL) { tempPtr = tempPtr-> next; } tempPtr-> next = newNode; } ++bucketSize[key]; ++totElems; }}/* End of Append */ template<class ItemType>bool HashTable<ItemType>::Remove(ItemType deleteItem, int key){ bool isFound = false; node* tempPtr; if(key == -1) { key = Hash(deleteItem); } if(IsEmpty(key)) { //std::cout<<"nREMOVE ERROR - HASH TABLE EMPTYn"; } else if(head[key]->currentItem == deleteItem) { tempPtr = head[key]; head[key] = head[key]-> next; delete tempPtr; --totElems; --bucketSize[key]; isFound = true; } else { for(tempPtr = head[key];tempPtr->next!=NULL;tempPtr=tempPtr->next) { if(tempPtr->next->currentItem == deleteItem) { node* deleteNode = tempPtr->next; tempPtr-> next = tempPtr-> next-> next; delete deleteNode; isFound = true; --totElems; --bucketSize[key]; break; } } } return isFound;}/* End of Remove */ template<class ItemType>void HashTable<ItemType>::Sort(int key){ if(IsEmpty(key)) { //std::cout<<"nSORT ERROR - HASH TABLE EMPTYn"; } else { int listSize = BucketSize(key); bool sorted = false; do{ sorted = true; int x = 0; for(node* tempPtr = head[key]; tempPtr->next!=NULL && x < listSize-1; tempPtr=tempPtr->next,++x) { if(tempPtr-> currentItem > tempPtr->next->currentItem) { ItemType temp = tempPtr-> currentItem; tempPtr-> currentItem = tempPtr->next->currentItem; tempPtr->next->currentItem = temp; sorted = false; } } --listSize; }while(!sorted); }}/* End of Sort */ template<class ItemType>int HashTable<ItemType>::TableSize(){ return hashSize;}/* End of TableSize */ template<class ItemType>int HashTable<ItemType>::TotalElems(){ return totElems;}/* End of TotalElems */ template<class ItemType>int HashTable<ItemType>::BucketSize(int key){ return(!IsEmpty(key)) ? bucketSize[key]:0;}/* End of BucketSize */ template<class ItemType>int HashTable<ItemType>::Count(ItemType searchItem){ int key = Hash(searchItem); int search = 0; if(IsEmpty(key)) { //std::cout<<"nCOUNT ERROR - HASH TABLE EMPTYn"; } else { for(node* tempPtr = head[key];tempPtr!=NULL;tempPtr=tempPtr->next) { if(tempPtr->currentItem == searchItem) { ++search; } } } return search;}/* End of Count */ template<class ItemType>void HashTable<ItemType>::MakeEmpty(){ totElems = 0; for(int x=0; x < hashSize; ++x) { if(!IsEmpty(x)) { //std::cout << "Destroying nodes ...n"; while(!IsEmpty(x)) { node* temp = head[x]; //std::cout << temp-> currentItem <<std::endl; head[x] = head[x]-> next; delete temp; } } bucketSize[x] = 0; }}/* End of MakeEmpty */ template<class ItemType>HashTable<ItemType>::~HashTable(){ MakeEmpty(); delete[] head; delete[] bucketSize;}/* End of ~HashTable */ // END OF THE HASH TABLE CLASS// -----------------------------------------------------------// START OF THE HASH TABLE ITERATOR CLASS template <class ItemType>class HashTable<ItemType>::Iterator : public std::iterator<std::forward_iterator_tag,ItemType>, public HashTable<ItemType> {public: // Iterator constructor Iterator(node* otherIter = NULL) { itHead = otherIter; } ~Iterator() {} // The assignment and relational operators are straightforward Iterator& operator=(const Iterator& other) { itHead = other.itHead; return(*this); } bool operator==(const Iterator& other)const { return itHead == other.itHead; } bool operator!=(const Iterator& other)const { return itHead != other.itHead; } bool operator<(const Iterator& other)const { return itHead < other.itHead; } bool operator>(const Iterator& other)const { return other.itHead < itHead; } bool operator<=(const Iterator& other)const { return (!(other.itHead < itHead)); } bool operator>=(const Iterator& other)const { return (!(itHead < other.itHead)); } // Update my state such that I refer to the next element in the // HashTable. Iterator operator+(int incr) { node* temp = itHead; for(int x=0; x < incr && temp!= NULL; ++x) { temp = temp->next; } return temp; } Iterator operator+=(int incr) { for(int x=0; x < incr && itHead!= NULL; ++x) { itHead = itHead->next; } return itHead; } Iterator& operator++() // pre increment { if(itHead != NULL) { itHead = itHead->next; } return(*this); } Iterator operator++(int) // post increment { node* temp = itHead; this->operator++(); return temp; } ItemType& operator[](int incr) { // Return "junk" data // to prevent the program from crashing if(itHead == NULL || (*this + incr) == NULL) { return junk; } return(*(*this + incr)); } // Return a reference to the value in the node. I do this instead // of returning by value so a caller can update the value in the // node directly. ItemType& operator*() { // Return "junk" data // to prevent the program from crashing if(itHead == NULL) { return junk; } return itHead->currentItem; } ItemType* operator->() { return(&**this); }private: node* itHead; ItemType junk;};#endif // http://programmingnotes.org/
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The iterator class starts on line #368, and is built to support most of the standard relational operators, as well as arithmetic operators such as ‘+,+=,++’ (pre/post increment). The * (star), bracket [] and -> arrow operators are also supported. Click here for an overview demonstrating how custom iterators can be built.
The rest of the code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Looking for sample code for a Hash Map? Click here!
===== DEMONSTRATION HOW TO USE =====
Use of the above template class is the same as many of its STL template class counterparts. Here are sample programs demonstrating its use.
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586
// DEMONSTRATE USE OF THE REMOVE AND SORT FUNCTIONS#include <iostream>#include <ctime>#include <string>#include <cstdlib>#include <iomanip>#include "HashTable.h"using namespace std; // iterator declarationstypedef HashTable<string>::Iterator strIterDec; // hash table sizeconst int TABLE_SIZE = 5; int main(){ // delcare variables srand(time(NULL)); const string names[]={"Alva","Edda","Hiram","Lemuel","Della","Roseann","Sang", "Evelia","Claire","Marylou","Magda","Irvin","Reagan","Deb","Hillary", "Tuyetm","Cherilyn","Amina","Justin","Neville","Jessica","Demi", "Graham","Cinderella","Freddy","Vivan","Marjorie","Krystal","Liza", "Spencer","Jordon","Bernie","Geraldine","Kati","Jetta","Carmella", "Chery","Earlene","Gene","Lorri","Albertina","Ula","Karena","Johanna", "Alex","Tobias","Lashawna","Domitila","Chantel","Deneen","Nigel", "Lashanda","Donn","Theda","Many","Jeramy","Jodee","Tamra","Dessie", "Lawrence","Jaime","Basil","Roger","Cythia","Homer","Lilliam","Victoria", "Tod","Harley","Meghann","Jacquelyne","Arie","Rosemarie","Lyndon","Blanch", "Kenneth","Perkins","Kaleena"}; int nameLen = sizeof(names)/sizeof(names[0]); // Hash table class declarations HashTable<string> strHash(TABLE_SIZE); // insert 10 items into each hash table for(int x=0; x < (TABLE_SIZE*2); ++x) { // place all data in bucket 0 // NOTE: you dont want to place all data into one // bucket, this is done for demo purposes only // Normally use the "Insert" function instead strHash.Append(0,names[rand()%(nameLen-1)]); } // assign the iterator to bucket 0 strIterDec it = strHash.begin(0); // display bucket size cout<<"Bucket #0 has "<<strHash.BucketSize(0)<<" items"<<endl; // display the first item cout<<"The first element in bucket #0 is "<< it[0] <<endl; // remove the first item in bucket 0 // NOTE: the second parameter is optional // but since we know we want bucket 0, we use it here strHash.Remove(it[0],0); // update the iterator to the new table state it = strHash.begin(0); // display the new first item cout<<"nNow bucket #0 has "<<strHash.BucketSize(0)<<" items"<<endl; cout<<"The first element in bucket #0 is "<< it[0] <<endl; // display all the items within the "strHash" table cout<<"nThe unsorted items in strHash bucket #0:n"; for(int x=0; x < strHash.BucketSize(0); ++x) { cout << "it[] = " << it[x] << endl; } // sort the items in bucket 0 strHash.Sort(0); // display all the items within the "strHash" table cout<<"nThe sorted items in strHash bucket #0:n"; for(int x=0; x < strHash.BucketSize(0); ++x) { cout << "it[] = " << it[x] << endl; } return 0;}// http://programmingnotes.org/
SAMPLE OUTPUT:
Bucket #0 has 10 items
The first element in bucket #0 is HomerNow bucket #0 has 9 items
The first element in bucket #0 is TamraThe unsorted items in strHash bucket #0:
it[] = Tamra
it[] = Lyndon
it[] = Johanna
it[] = Perkins
it[] = Alva
it[] = Jordon
it[] = Neville
it[] = Lawrence
it[] = Jetta
The sorted items in strHash bucket #0:
it[] = Alva
it[] = Jetta
it[] = Johanna
it[] = Jordon
it[] = Lawrence
it[] = Lyndon
it[] = Neville
it[] = Perkins
it[] = Tamra
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122
// DISPLAY ALL DATA INSIDE TABLE USING STD::STRING / INT / STRUCT#include <iostream>#include <ctime>#include <string>#include <cstdlib>#include <iomanip>#include "HashTable.h"using namespace std; // sample struct demostruct MyStruct{ string name;}; // iterator declarationstypedef HashTable<string>::Iterator strIterDec;typedef HashTable<int>::Iterator intIterDec;typedef HashTable<MyStruct>::Iterator strctIterDec; // hash table sizeconst int TABLE_SIZE = 10; int main(){ // delcare variables srand(time(NULL)); const string names[]={"Alva","Edda","Hiram","Lemuel","Della","Roseann","Sang", "Evelia","Claire","Marylou","Magda","Irvin","Reagan","Deb","Hillary", "Tuyetm","Cherilyn","Amina","Justin","Neville","Jessica","Demi", "Graham","Cinderella","Freddy","Vivan","Marjorie","Krystal","Liza", "Spencer","Jordon","Bernie","Geraldine","Kati","Jetta","Carmella", "Chery","Earlene","Gene","Lorri","Albertina","Ula","Karena","Johanna", "Alex","Tobias","Lashawna","Domitila","Chantel","Deneen","Nigel", "Lashanda","Donn","Theda","Many","Jeramy","Jodee","Tamra","Dessie", "Lawrence","Jaime","Basil","Roger","Cythia","Homer","Lilliam","Victoria", "Tod","Harley","Meghann","Jacquelyne","Arie","Rosemarie","Lyndon","Blanch", "Kenneth","Perkins","Kaleena"}; int nameLen = sizeof(names)/sizeof(names[0]); // Hash table class declarations HashTable<string> strHash(TABLE_SIZE); HashTable<int> intHash = TABLE_SIZE; HashTable<MyStruct> strctHash = TABLE_SIZE; // access struct element MyStruct strctAccess; // insert 20 items into each hash table for(int x=0; x < (TABLE_SIZE*2); ++x) { // Use the "insert" function to place data into the hash table // this function automatically hashes the basic datatypes // i.e: int, double, char, char*, string strHash.Insert(names[rand()%(nameLen-1)]); intHash.Insert(rand()%10000); // The "insert" function cant be used on a struct, so we // use the "append" function for the struct declaration. // We use the "strHash" class declaration to use its // hash function, then place the struct in an appropriate // hashed bucket strctAccess.name = names[rand()%(nameLen-1)]; int strctHashKey = strHash.Hash(strctAccess.name); strctHash.Append(strctHashKey,strctAccess); } // display all the items within the "strHash" table for(int x=0; x < strHash.TableSize(); ++x) { if(!strHash.IsEmpty(x)) { cout<<"nstrHash Bucket #"<<x<<":n"; for(strIterDec it = strHash.begin(x); it != strHash.end(x); it+=1) { // access elements using the * (star) operator cout << "*it = " << *it << endl; } } } // creates a line seperator cout<<endl; cout.fill('-'); cout<<left<<setw(80)<<""<<endl; // display all the items within the "intHash" table for(int x=0; x < intHash.TableSize(); ++x) { intIterDec it = intHash.begin(x); if(!intHash.IsEmpty(x)) { cout<<"nintHash Bucket #"<<x<<":n"; for(int y = 0; y < intHash.BucketSize(x); ++y) { // access elements using the [] operator cout << "it[] = " << it[y] << endl; } } } // creates a line seperator cout<<endl; cout.fill('-'); cout<<left<<setw(80)<<""<<endl; // display all the items within the "strctHash" table for(int x=0; x < strctHash.TableSize(); ++x) { if(!strctHash.IsEmpty(x)) { cout<<"nstrctHash Bucket #"<<x<<":n"; for(strctIterDec it = strctHash.begin(x); it!=strctHash.end(x); it=it+1) { // access struct/class elements using the -> operator cout << "it-> = " << it->name << endl; } } } return 0;}// http://programmingnotes.org/
SAMPLE OUTPUT:
strHash Bucket #0:
*it = Cinderella
*it = Perkins
*it = Krystal
*it = Roger
*it = RogerstrHash Bucket #1:
*it = Lilliam
*it = Lilliam
*it = ThedastrHash Bucket #2:
*it = AriestrHash Bucket #3:
*it = MagdastrHash Bucket #6:
*it = Edda
*it = Irvin
*it = Kati
*it = LyndonstrHash Bucket #7:
*it = Deb
*it = JaimestrHash Bucket #8:
*it = Neville
*it = VictoriastrHash Bucket #9:
*it = Chery
*it = Evelia--------------------------------------------
intHash Bucket #0:
it[] = 2449
it[] = 6135intHash Bucket #1:
it[] = 1120
it[] = 852intHash Bucket #2:
it[] = 5727intHash Bucket #3:
it[] = 1174intHash Bucket #4:
it[] = 2775
it[] = 3525
it[] = 8375intHash Bucket #5:
it[] = 4322
it[] = 8722
it[] = 5016intHash Bucket #6:
it[] = 5053
it[] = 7231
it[] = 1571intHash Bucket #7:
it[] = 1666
it[] = 4510
it[] = 1548
it[] = 3646intHash Bucket #9:
it[] = 2756--------------------------------------------
strctHash Bucket #0:
it-> = Cherilyn
it-> = RogerstrctHash Bucket #1:
it-> = Tamra
it-> = Alex
it-> = ThedastrctHash Bucket #2:
it-> = Nigel
it-> = Alva
it-> = AriestrctHash Bucket #4:
it-> = BasilstrctHash Bucket #5:
it-> = TodstrctHash Bucket #6:
it-> = Irvin
it-> = LyndonstrctHash Bucket #7:
it-> = Amina
it-> = Hillary
it-> = Kenneth
it-> = AminastrctHash Bucket #8:
it-> = Gene
it-> = Lemuel
it-> = Gene
strctHash Bucket #9:
it-> = Albertina








Leave a Reply